
Placebo-Controlled Trials: What Researchers Must Understand
Placebo controlled trials are where good science either proves itself or quietly breaks. You can have a great protocol and still end up with unblinding, biased assessments, noisy endpoints, and a placebo response that buries your drug signal. The teams that win treat placebo as a system, not a pill: expectations, site behavior, data capture, monitoring, randomization, and safety surveillance all interact. This guide breaks down what researchers must understand to run placebo controlled studies that stay credible under scrutiny and still recruit in the real world.
1) Why placebo control is still the hardest design to execute well
A placebo arm is not just a comparator. It is a stress test for everything that can bias results. When you add placebo, you are declaring that blinding will hold, that assessments will be consistent, and that your trial will not accidentally teach participants and sites how to guess allocation. If any of those assumptions fail, your effect size shrinks, variance increases, and you can end up with a “negative” trial that is really a conduct problem.
Operationally, placebo exposes weak processes faster than active controlled designs. A sloppy site can drift into behavior that changes participant expectations. A rushed enrollment push can lower baseline severity and inflate placebo response. An unclear endpoint can turn visits into coaching sessions instead of standardized measurement. Those problems show up as messy data, inconsistent assessments, and preventable protocol deviations. This is why roles such as a strong clinical research coordinator and a capable clinical research associate matter more in placebo controlled trials than teams like to admit.
Placebo is also where design meets ethics. If standard of care exists, a placebo alone can be indefensible. If symptoms are severe, rescue therapy must be thoughtfully built in. If participants are vulnerable, consent must be unambiguous about uncertainty, risks, and what “placebo” actually means in practice. A credible team connects ethics, operations, and measurement from the first protocol draft, and uses tools like clean case report form best practices and realistic recruitment assumptions, not hope.
| Element | What to verify | Why it matters | Common failure mode | Best practice |
|---|---|---|---|---|
| Scientific justification | Clear need for placebo vs active control | Protects credibility with IRBs and regulators | “Because it is standard” reasoning | Tie to uncertainty, outcome sensitivity, and feasibility |
| Assay sensitivity | Trial can detect a real effect if present | Avoids false negatives | Endpoints too subjective, site drift | Standardize assessments and train raters |
| Blinding plan | Who is blinded and how maintained | Bias control is the whole point | Side effects reveal allocation | Match appearance, schedule, and procedures |
| Randomization method | Appropriate method for sites and strata | Prevents imbalance and gaming | Predictable blocks at small sites | Centralized randomization with concealment |
| Allocation concealment | No one can infer assignments pre dose | Stops selection bias | Staff learn patterns | Use secure systems and audit trails |
| Placebo manufacturing | Indistinguishable look and handling | Supports blinding integrity | Taste or packaging mismatch | QC for appearance, smell, texture, labeling |
| Rescue medication | Clear criteria and documentation | Ethical safety valve | Rescue used inconsistently | Protocolize triggers and capture timing precisely |
| Standard of care | Background therapy allowed and stable | Controls confounding | Sites change concomitant meds mid study | Lock down stable regimens and educate sites |
| Eligibility severity threshold | Baseline severity adequate for signal | Low severity inflates placebo response | Enrollment pressure lowers thresholds | Central review or rater confirmation |
| Endpoint selection | Clinically meaningful and reliable | Reduces noise and bias | Overly subjective endpoints | Use validated scales and objective anchors |
| Visit schedule | Feasible and consistent across arms | Differential attention can drive placebo | Extra follow ups in one arm | Standardize contact frequency and scripts |
| Expectation management | Consent language and staff messaging | Expectations move outcomes | Staff “sell” the drug unconsciously | Neutral scripts and role play training |
| Rater training | Standardization across sites and time | Protects measurement integrity | Rater drift and coaching | Calibration, refreshers, and central checks |
| CRF structure | Captures what drives bias and rescue | Missing fields kill interpretability | Free text and inconsistent coding | Tight fields, clear definitions, edit checks |
| Missing data plan | Pre specified estimand and handling | Avoids biased conclusions | Dropout differs by perceived assignment | Retention plan plus sensitivity analyses |
| Adherence monitoring | Objective adherence checks | Nonadherence dilutes signal | Self report only | Pill counts, device logs, or biomarkers |
| Site selection | Capability with blinded procedures | Sites drive placebo variability | High turnover, poor training culture | Choose stable teams with audit readiness |
| Monitoring focus | Detect unblinding and rater drift early | Prevents irreversible bias | Monitors check boxes, miss conduct signals | Risk based monitoring with behavior triggers |
| Unblinding handling | When and how emergency unblinding occurs | Keeps safety and integrity aligned | Unblinding used for convenience | Strict criteria, documentation, independent process |
| Adverse event capture | Neutral elicitation methods | Avoids differential reporting | Leading questions bias AE patterns | Use standardized AE scripts and timing |
| Safety signal review | Independent oversight cadence | Ensures ethical continuation | Late detection due to poor aggregation | Central safety team with rapid query resolution |
| Statistical power | Assumptions include placebo response and variance | Underpowering wastes the trial | Optimistic placebo assumptions | Use realistic priors and sensitivity ranges |
| Data review cadence | Clean data fast enough to intervene | Bias compounds over time | Queries backlogged until DBL | Weekly metrics and rapid site feedback loops |
| Protocol deviation controls | Root cause tracking and prevention | Deviations often correlate with unblinding | Repeated deviations treated as “normal” | Trend reports and retraining thresholds |
| Transparency and reporting | Pre registration and clear analysis plan | Protects trust in results | Post hoc endpoint switching | Lock SAP early and document amendments |
2) When placebo control is appropriate and when it becomes a trap
The right question is not “Can we use placebo?” The real question is “Does placebo answer the decision we must make without exposing participants to unacceptable risk?” When no proven therapy exists, placebo can be the cleanest way to measure benefit and risk, especially when endpoints are subjective and expectations can amplify perceived improvement. When an effective therapy exists, placebo can still be acceptable, but usually only as an add on design where everyone receives standard therapy and placebo tests incremental benefit.
Placebo becomes a trap when it is used to simplify development decisions at the cost of external credibility. If the disease has serious consequences, withholding effective therapy can create ethical pushback and poor recruitment. If participants have access to real world treatment, they may drop out, seek outside meds, or “stack” supplements, and those behaviors can destroy interpretability. If your study population is mild because you recruited too broadly, placebo response often rises and your drug signal shrinks. That is why teams lean on clean baseline definitions, realistic inclusion criteria, and disciplined site oversight with well trained CRA monitoring practices and capable site leadership.
Operationally, you must anticipate where ethics and execution collide. Rescue therapy is not a footnote. It is a design feature that needs exact triggers, clean documentation, and analysis planning. If rescue is inconsistent, the trial turns into a site culture comparison. If rescue is overused, your ability to detect benefit fades. If rescue is underused, safety and retention suffer. That entire chain depends on the site’s workflow and documentation habits, so your CRF structure and your coordinator execution quality can make or break the study.
3) Blinding is a behavioral problem, not a packaging problem
Most teams treat blinding as a manufacturing challenge. Match the capsule, match the label, and move on. That is how unblinding sneaks in. Blinding fails because humans interpret patterns. Participants interpret symptom changes and side effects. Coordinators interpret how people talk, how they react, and how eager they are to continue. Investigators interpret lab shifts and visit narratives. Even if packaging is perfect, behavior can still reveal allocation.
The first blinding leak often comes from side effects. If the investigational product has recognizable effects, participants and staff begin to guess. When that happens, outcomes change. Participants who believe they are on active therapy may report better symptoms, try harder, or stay engaged. Participants who believe they are on placebo may disengage, seek outside treatments, or rate symptoms as worse to justify withdrawing. This turns into differential dropout and differential reporting, which becomes a statistical and interpretive nightmare. The fix is to plan for it: neutral AE elicitation, consistent visit scripts, and careful endpoint administration that avoids coaching.
Randomization and concealment also interact with blinding. If sites can infer the next assignment, you create selection bias and expectation bias at the same time. Even a solid design can be undermined by predictable block sizes at small sites. Centralized systems, strong concealment, and thoughtful implementation are not optional. If you need a refresher on where teams get this wrong, the breakdown of randomization techniques in clinical trials connects directly to the blinding failures you see in placebo controlled studies.
Measurement discipline is the other half of blinding. If raters drift or improvise, assessments become inconsistent and placebo response rises. If coordinators “help” participants answer, you stop measuring the endpoint and start manufacturing it. Training, calibration, and ongoing quality checks are the core defense. This is where pairing a strong site with skilled monitoring and clear documentation expectations pays off. The closer your trial is to a behavioral endpoint, the more it needs disciplined execution, not just a good protocol.
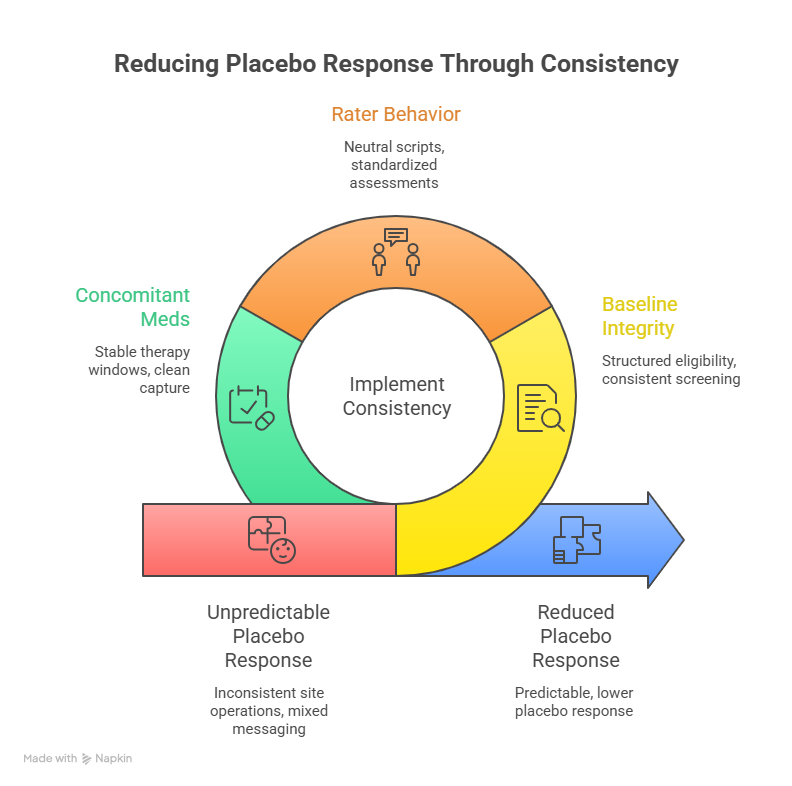
4) How to reduce placebo response without compromising ethics
You cannot “outsmart” placebo response by making the consent scary or by downplaying benefits. That backfires and damages trust. The goal is to reduce unnecessary variability and expectation driven swings while keeping participants informed and respected. The most effective lever is consistency. When sites run visits differently, when raters interpret scales differently, and when participants receive mixed messaging, placebo response becomes unpredictable and often larger.
Start with baseline integrity. If your population has low symptom severity, a small improvement looks big, and regression to the mean can masquerade as placebo benefit. Enrollment pressure can quietly shift baseline thresholds downward. The defense is structured eligibility confirmation, consistent screening procedures, and documentation that allows sponsors and monitors to detect drift early. Coordinators should capture baseline history in a disciplined way using strong CRF design practices rather than loose narratives that cannot be compared across participants.
Then address rater behavior. Placebo response rises when assessments become therapeutic conversations. Participants feel heard, feel supported, and report improvement even when the drug has no effect. That does not mean you should be cold. It means you must separate care from measurement. Use neutral scripts, avoid leading questions, and standardize the order and pacing of assessments. Monitoring should focus on rater drift and protocolized conduct, not just missing signatures. This is where strong CRA skill sets change outcomes, because the monitor can detect behavioral patterns that pure data checks miss.
Finally, treat concomitant meds and rescue as placebo multipliers. If rescue use varies widely, the placebo arm might look better or worse for reasons unrelated to true response. If sites allow symptom improving non study meds inconsistently, your endpoint becomes contaminated. You can reduce this risk by defining stable background therapy windows, capturing changes cleanly, and training sites to treat these rules as core scientific integrity requirements, not administrative friction.
5) Data integrity and safety surveillance in placebo controlled trials
In placebo controlled trials, safety reporting is not only about protection. It is also about interpreting benefit risk correctly. If adverse events are elicited differently across arms, staff can unknowingly reveal allocation and bias reporting. If participants think they are on placebo, they might attribute symptoms to the disease and underreport. If participants think they are on active therapy, they might over report because they believe they should be feeling something. Standardized AE elicitation protects both safety and blinding.
This is where pharmacovigilance thinking matters inside the trial, not only after approval. Teams that understand pharmacovigilance fundamentals build neutral and consistent safety workflows. They also design queries and coding practices to avoid creating patterns that hint at allocation. Safety review should be timely enough to address emerging issues without forcing sites into panic behavior that changes participant experience.
Data quality is equally strategic. If queries pile up until late, sites forget context, correct data loosely, and introduce noise. If the CRF allows ambiguous entries, endpoints become hard to interpret. If protocol deviations are treated as isolated incidents rather than patterns, the same issues repeat until the database lock. A disciplined team uses frequent data review, tracks root causes, and treats repeated deviations as an execution risk that demands intervention.
Statistical planning should align with how placebo controlled trials fail in real life. Assumptions should incorporate realistic placebo response and variance. Missing data plans should account for differential dropout driven by perceived assignment. Sensitivity analyses should be pre specified, not invented after results disappoint. If you want an approachable bridge into why these choices matter, a beginner friendly overview of biostatistics in clinical trials helps translate operational behavior into statistical consequences.
6) FAQs on placebo controlled trials
-
Most failures are execution failures that create bias and noise. Unblinding, rater drift, inconsistent rescue use, and enrollment of low severity participants can erase an otherwise real treatment effect. The protocol can describe perfect conduct, but site behavior is where placebo response grows. Strong teams invest in consistent endpoint administration, clean case report form implementation, and tight monitoring that focuses on behavior triggers, not only missing fields. When operational discipline is treated as a scientific variable, not an administrative burden, placebo controlled trials stop collapsing under their own variability.
-
It is unethical when withholding effective therapy exposes participants to serious harm, or when the design removes access to a standard treatment without strong justification and protections. In many conditions, placebo can still be used ethically if participants continue standard of care and placebo represents the add on comparator. Ethics also depends on rescue therapy, monitoring intensity, and informed consent clarity. If the trial design depends on participants enduring avoidable worsening without a safety valve, recruitment and retention will suffer and ethics review will tighten. Ethical design is practical design because it reduces dropout and protects interpretability.
-
They accept that packaging alone is not enough and plan for behavior. Neutral AE elicitation, consistent visit scripts, and standardized assessment timing reduce inference. Staff must avoid “confirming” participant guesses through tone or extra attention. Emergency unblinding needs strict criteria and independent handling to prevent convenience unblinding that spreads across a site. Allocation concealment also matters, so the randomization approach should resist predictability, especially at small sites. If you need a grounded framework for this, the CCRPS breakdown of randomization techniques links directly to how blinding is protected in practice.
-
Reduce variability, not honesty. Tighten baseline integrity, standardize endpoint administration, and remove site to site differences in participant contact. Train raters to avoid coaching and drifting, and ensure eligibility thresholds do not slide under enrollment pressure. Control concomitant meds and rescue rules consistently and document them cleanly. Also monitor early for signs of measurement inflation, such as suspiciously fast improvements or inconsistent scoring patterns. A placebo response is not “fake,” but it can become exaggerated when the trial environment becomes inconsistent or emotionally loaded.
-
Because more forms of bias become trial ending. If staff infer allocation, behavior changes and outcomes shift. If protocol deviations cluster around dosing, assessments, or rescue rules, the placebo comparator becomes contaminated. A strong clinical research associate does more than verify documents. They detect patterns in site conduct, retrain teams before drift becomes irreversible, and protect the trial’s credibility. Placebo controlled trials magnify small conduct errors into large interpretive problems, so monitoring must be proactive, not reactive.
-
Rescue must be protocolized with clear triggers, consistent documentation, and analysis planning. Sites should not treat rescue as a subjective comfort decision because inconsistent rescue use becomes a hidden confounder. The CRF should capture rescue timing, dose, reason, and relation to endpoint assessments. Training should emphasize that rescue is both an ethical safeguard and a scientific variable. When rescue is applied consistently, it protects participants and preserves interpretability. When rescue is chaotic, it creates differential exposure and can make placebo and active arms incomparable in practice.
-
Ambiguous endpoints, inconsistent CRF entries, missing context for protocol deviations, and poor traceability around unblinding and rescue are common problems. Reviewers want to see that the trial measured what it claimed to measure, that deviations were understood and managed, and that blinding was protected as a system. Clean CRF best practices matter because they determine whether data can be trusted and interpreted. Good documentation is not padding. It is the audit trail that proves your results came from disciplined measurement, not hopeful storytelling.