
Vendor Management in Clinical Trials: Essential PM Skills
Vendor management is where clinical trials quietly win or bleed out. A “great protocol” still fails if your CRO can’t staff, your lab can’t hit TAT, your EDC build slips, your PV vendor mishandles timelines, or your central IRB creates avoidable cycle time. This guide is the PM skills playbook: how to select vendors fast, contract intelligently, govern performance, prevent hidden scope creep, and build escalation systems that protect data integrity, timelines, and patient safety—without becoming a micromanager.
If you’ve ever dealt with vague SOWs, “that’s out of scope” surprises, messy handoffs, and dashboards that look healthy while deliverables rot—this is built for you.
1. Why Vendor Management Decides Trial Outcomes (Not the Gantt Chart)
Most trials don’t fail because teams “didn’t work hard.” They fail because the vendor system wasn’t designed for reality: changing enrollment velocity, amendments, data cleaning spikes, query storms, safety case volume swings, and site variability that destroys fixed assumptions. If you want predictable execution, your PM job is to engineer predictability into vendors: scope clarity, measurable outputs, governance rhythm, and frictionless escalation.
Here’s what separates amateurs from trial-ready PMs:
They manage interfaces, not vendors. The biggest failures happen between vendors: CRO ↔ central lab, CRO ↔ imaging core, EDC ↔ eCOA, PV ↔ medical monitor, sites ↔ payment vendor. If the interfaces aren’t defined, you get “everyone did their part” while the trial collapses.
They build oversight proportional to risk. A low-risk translation vendor doesn’t need the same governance as your CRO, PV, or EDC build partner. Align intensity with risk-based oversight logic used in monitoring. (If you’re sharpening your monitoring lens, revisit the CRA fundamentals here: Clinical Research Associate (CRA) Roles, Skills & Career Path.)
They protect data flow like a product manager protects production. Data quality isn’t “fixed later.” It’s designed upfront through CRF logic, edit checks, reconciliation rules, and handoffs. If CRFs are sloppy, every downstream vendor suffers—start with a strong foundation: Case Report Form (CRF) Definition, Types & Best Practices.
Vendor management is also where you prevent regulatory pain. If your vendor chain can’t produce inspection-ready evidence, you’re building risk into the trial from day one. Anchor your documentation thinking with: Managing Regulatory Documents: Comprehensive Guide for CRCs and keep your operational reality grounded in site workflows via: Clinical Research Coordinator (CRC) Responsibilities & Certification.
2. The Vendor Lifecycle: 6 PM Skills That Prevent Scope Creep, Delays, and Quality Drift
A trial-ready PM runs vendors through a lifecycle that’s repeatable. Not “we’ll figure it out as we go.” Repeatable.
1) Translate protocol complexity into vendor complexity (before you shop)
Vendors price what you say, not what you need. If your study has complex endpoints, blinding, randomization, or frequent assessments, your vendor risk multiplies. That’s why PMs need to understand the mechanics:
Randomization edge cases drive IRT change orders: Randomization Techniques in Clinical Trials Explained Clearly
Blinding complexity increases operational failure points: Blinding in Clinical Trials: Types & Importance Clearly Explained
Endpoint ambiguity causes downstream chaos in stats, imaging, DM: Primary vs Secondary Endpoints Clarified (With Examples)
PM move: run a “vendor-impact workshop” with Ops, DM, Stats, PV, and Med Monitor. Output is a single page: what complexity exists, which vendor touches it, and what it does to cost/timelines.
2) Build a RACI that names handoffs (not just roles)
Most vendor RACIs are cosmetic. A useful RACI names handoff objects:
“Who produces annotated CRF?”
“Who owns edit check specs?”
“Who reconciles PV ↔ EDC?”
“Who signs off on UAT evidence?”
Anchor your data thinking with Biostatistics in Clinical Trials: A Beginner-Friendly Overview so you don’t treat “analysis” as magic at the end.
3) Turn vendor promises into measurable outputs
“High quality” is not measurable. “On-time” is meaningless without definitions. Replace vague promises with acceptance criteria:
Deliverable definition (what “done” means)
Evidence required (files, logs, screenshots, sign-offs)
SLA clock (when timing starts/ends)
Rework rules (what triggers rework and who pays)
PM move: define 5–10 “must-not-fail” metrics per critical vendor and review them weekly.
4) Design governance cadence like a control system
A vendor governance system has:
Weekly operating call (execution)
Biweekly risk review (forward-looking)
Monthly financial review (burn vs forecast)
Quarterly quality review (CAPA trends)
This is how you avoid the classic failure mode: “Everything looked fine until it wasn’t.”
If you’re mapping where talent comes from (CROs, vendors, contractors), these directories help you understand the ecosystem:
3. Contracting & SOW Design: The PM Skills That Stop “Out of Scope” Ambushes
SOW failures are predictable. They happen when the PM doesn’t force clarity on volume, change, and ownership.
The 7 clauses that save your trial
Volume model (what is the unit, and what drives it?)
Cases per month, queries per subject, sites activated per quarter, visits per site. Use ranges, not single numbers.Change control thresholds
Define when a change becomes a paid change (e.g., “>10% increase in CRF pages” or “>2 protocol amendments with impact to IRT rules”).Named resources / key person clauses
If performance depends on talent, lock the talent. Otherwise you’ll get the “A-team in sales, B-team in execution” trap.Subcontractor transparency
If the vendor subcontracts labs, monitoring, translation—make it explicit and govern it.Acceptance criteria + rejection rights
If deliverables are not usable, you need contractual ability to reject and require rework without renegotiation.Escalation ladder
Not “email us.” A timed ladder: 24h → 72h → executive escalation.Data access and export rights
If you can’t extract your data cleanly, you don’t own your trial.
PM move: For any system touching efficacy or safety, treat deliverables like regulated evidence. That mindset aligns with safety seriousness covered here: What Is Pharmacovigilance? Essential Guide for Clinical Research.
Also, if your design includes placebo or controls, your operational expectations shift (enrollment behavior, retention, AE patterns, site burden). Bake that into vendor assumptions: Placebo-Controlled Trials: What Researchers Must Understand.
4. Performance Governance: How to Run Vendor Meetings That Actually Control Outcomes
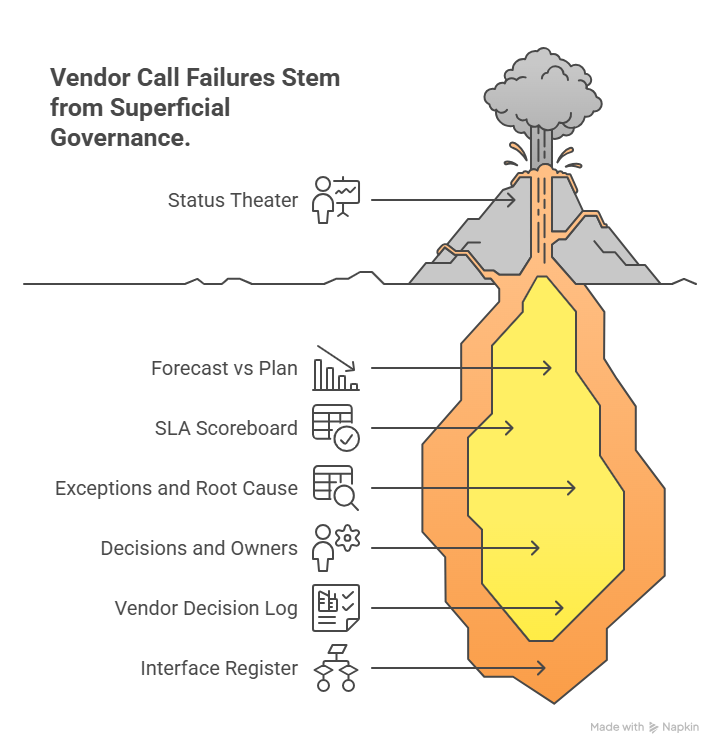
Vendor calls fail when they become status theater. High-performing PMs run governance like an ops control room.
The agenda that stops “pretty updates”
1) Forecast vs plan (next 2–4 weeks)
Enrollment forecast changes → what breaks?
Amendments → what vendors must change?
Data cleaning spikes → capacity impact?
2) SLA scoreboard (only the few metrics that matter)
Aging of queries, deviations, cases, kit exceptions
TAT by vendor function
Backlog in “work not started” state
3) Exceptions and root cause (not symptoms)
If queries are high: is it CRF design, site training, edit checks, or monitoring quality? Link your monitoring thinking to CRA execution realities: Clinical Research Associate (CRA) Roles, Skills & Career Path.
4) Decisions and owners (with deadlines)
A vendor meeting that ends without owners is a waste. Every decision gets:
owner
due date
evidence required
escalation path if missed
PM move: Maintain a “Vendor Decision Log” and “Interface Register.” The interface register lists every cross-vendor data transfer and handoff, with owner and test evidence.
If your oversight includes independent committees or interim safety reviews, treat pack delivery as a hard SLA, not a suggestion: Data Monitoring Committee (DMC) Roles in Clinical Trials Explained.
5. Risk, Quality, and Escalation: The Playbook That Keeps You Inspection-Ready
The best PMs assume two things:
Something will go wrong.
The only question is whether you detect it early or late.
Build a vendor risk register that isn’t fake
Your risk register should include:
Leading indicators (early warning signals)
Trigger thresholds (when you escalate)
Mitigation actions (predefined moves)
Evidence of control (documentation you can show)
Examples of leading indicators:
Rising protocol deviation rate at specific sites (points to training or workflow issues—ground yourself in site ops: Clinical Research Coordinator (CRC) Responsibilities & Certification)
Increasing query volume tied to a specific eCRF page (points to CRF design: Case Report Form (CRF) Best Practices)
PV reconciliation delays (points to interface failure, not “PV is slow”: Pharmacovigilance Essential Guide)
Randomization/IRT rule changes requested late (points to inadequate upfront review: Randomization Techniques Explained)
Escalation systems that work under pressure
A real escalation ladder is timed and outcome-based:
Tier 1 (24h): functional lead + clear ask + deadline
Tier 2 (72h): vendor PM + sponsor PM + mitigation options
Tier 3 (5 business days): executive sponsors + contractual remedies + resourcing changes
PM move: Prewrite “escalation templates” so you don’t improvise under stress. Each escalation message should include:
impact (time, quality, safety)
evidence (metrics)
what you need by when
what happens if missed (next tier)
If you’re managing vendor tech stacks, keep a shortlist of platform ecosystems and compare maturity using:
6. FAQs: Vendor Management in Clinical Trials (PM-Level Answers)
-
Treating vendor management as relationship management instead of output control. You need measurable acceptance criteria, handoff ownership, and a governance cadence that catches drift early—especially for data flow vendors like EDC and DM (CRF best practices matter here).
-
Freeze requirements early (URS/specs), define change thresholds, and make interfaces explicit. Most change orders come from “we didn’t define what done means” and “handoffs weren’t scoped.” If your design has complex blinding/randomization, lock those rules with stakeholders upfront (blinding types + randomization techniques).
-
Matter: SLA adherence, backlog aging, defect/rework rates, reconciliation closure, cycle times, and exception closure time. Vanity: “% tasks completed” without quality evidence, dashboards that don’t tie to acceptance criteria, and reporting volume without action closure.
-
Force predictive reporting: next-2-week forecast, capacity view, and leading indicators. Require evidence, not statements (UAT logs, QC results, query aging). Tie this to a strict escalation ladder and decision log. Use independent oversight mindset when needed (DMC roles).
-
Intensity should match patient safety and data integrity impact. PV, EDC/DM, CRO monitoring, and anything tied to endpoints needs tighter cadence and documented control (pharmacovigilance overview + endpoints clarification).
-
Create a “site friction dashboard” (kits, payments, support tickets, training completion, query burden) and review it weekly with the CRO/site ops lead. Many delays originate at site workflows, so use CRC-grounded reality to guide fixes (CRC responsibilities).