
Blinding in Clinical Trials: Types & Importance Clearly Explained
Blinding is the difference between a trial that measures reality and a trial that measures belief. When participants, site staff, or outcome assessors can infer treatment assignment, behavior changes. Symptoms get reported differently, rescue medication gets used inconsistently, investigators subconsciously coach responses, and endpoints drift. The result is not just bias. It is noise that can bury a real effect or manufacture a fake one. This guide explains the main blinding types, why they matter, and how to prevent the unblinding failures that quietly ruin credibility.
1) What blinding actually controls and why trials fail without it
Blinding controls expectation driven distortion. In real studies, people do not just “receive” interventions. They interpret side effects, compare experiences in waiting rooms, read social media, and pick up cues from staff. Once expectations shift, endpoints shift, especially when outcomes are subjective or behavior dependent. That is why blinding is operational, not theoretical. The protocol can say “double blind,” but day to day site behavior decides whether it remains blind. Strong site execution, led by a capable clinical research coordinator, is what keeps blinding alive when timelines get tight and enrollment pressure rises.
Blinding failure often starts with predictable patterns and small “harmless” exceptions. Fixed block sizes can make allocation guessable, and staff begin acting on those guesses. That is why randomization and concealment are inseparable from blinding, and why teams revisit proven approaches from randomization techniques in clinical trials when blinding risk is high. Documentation can also create unblinding by accident. If adverse event prompts differ by arm, or CRFs capture side effects in a way that reveals assignment, the blind degrades quietly. Clean data design using CRF best practices is one of the fastest ways to reduce unblinding through documentation.
A second common failure is role confusion. Sites often treat blinding as a pharmacy task. In reality, the blind is a chain across enrollment scripts, visit flow, endpoint assessment, rescue medication, adverse event elicitation, and monitoring. A strong clinical research associate looks for behavioral signals of unblinding, not just missing signatures. That same monitoring discipline becomes even more critical when studies scale across sites, where inconsistency multiplies placebo response and endpoint variance, and where the trial’s statistical assumptions can collapse. If your team needs a practical way to translate conduct into statistics, this biostatistics overview helps you connect unblinding risk to real interpretability damage.
| Risk area | How unblinding happens | Early warning signal | Best control | Documentation note |
|---|---|---|---|---|
| Randomization predictability | Fixed blocks at small sites | Staff “guessing” correct often | Varying blocks, centralized concealment | Audit allocation access logs |
| Allocation concealment | Enrollment altered based on suspected arm | Screen fails spike near assignments | Secure IRT and restricted roles | Track screening reasons precisely |
| IP appearance | Capsule color or tablet imprint differs | Participant comments about looks | QC of look, smell, texture | Record complaints as protocol issue |
| Taste and sensation | Distinct taste, burning, numbing | Same sensation cluster in one arm | Sensory matched placebo strategy | Capture timing relative to dosing |
| Dosing schedule differences | Extra steps or labs in one arm | Visit duration differs by arm | Harmonize procedures across arms | Time stamps help detect drift |
| Side effect profile | Recognizable AE pattern reveals arm | High “I know I’m on drug” claims | Neutral AE scripts and training | Avoid leading AE questions |
| Rescue medication use | Rescue used more when placebo suspected | Rescue spikes after “guessing” | Clear rescue criteria and capture | Document triggers, timing, dose |
| Concomitant medication changes | Outside meds added when placebo suspected | New meds cluster by site | Stability windows and monitoring | Use structured CRF fields |
| Endpoint coaching | Staff guide participants to “good answers” | Too perfect score trajectories | Standard scripts, rater calibration | Source notes must match CRF |
| Rater drift | Raters change scoring over time | Variance increases mid study | Refresher training, central review | Track rater IDs per visit |
| Differential attention | Staff spend more time with suspected drug arm | Longer calls, extra check ins | Equalize contact and scripts | Log unscheduled contacts |
| Laboratory result clues | Known lab shifts reveal assignment | Staff discuss “expected” shifts | Limit access, standardize review | Role based access controls |
| Packaging logistics | Kit numbers map to treatment | Specific kits “always drug” rumors | Randomize kit assignment securely | Audit kit to subject mapping |
| Temperature handling | Different storage needs reveal arm | One arm always stored separately | Align storage and handling steps | Document excursions consistently |
| Injection site reactions | Visible reactions differ by arm | Participants compare injection effects | Matched placebo and neutral counseling | Capture severity with standard scale |
| Infusion time differences | Active infusion length differs | Nurses predict based on schedule | Standardize infusion duration | Record start stop times |
| Unblinded vendor access | Central labs or vendors leak info | Site hears “results by arm” | Firewalls and access restrictions | Vendor training documentation |
| Emergency unblinding abuse | Unblinding used for convenience | Unblinding rate higher than expected | Strict criteria, independent process | Require reason and outcome follow up |
| Staff turnover | New staff trained inconsistently | Process deviations increase after turnover | Onboarding checklist and refreshers | Track training dates and roles |
| Participant communication | Participants share side effect stories | Group chats form, rumors spread | Set expectations and boundaries early | Document counseling consistently |
| Investigator language | Investigator hints at assignment | Participants quote investigator opinions | Neutral phrasing, scripted guidance | Monitor visit notes for cues |
| Outcome assessor access | Assessor sees labs or AEs revealing arm | Assessor confidence increases over time | Separate roles and restrict data view | Access logs for assessor accounts |
| Data cleaning notes | Queries include treatment identifiers | Queries reference “typical drug AE” | Neutral query language | Standard templates for queries |
| Protocol deviation patterns | Deviations cluster after suspected placebo | Missed visits increase in one arm | Trend review and retraining thresholds | Track root cause consistently |
| Safety reporting bias | AEs elicited differently per expectation | AE profiles look “too clean” in placebo | Standard AE scripts, PV review | Consistency checks across sites |
2) Types of blinding explained clearly and how to choose the right one
Blinding types should be selected based on where bias can enter your trial. The simplest categories are single blind, double blind, and triple blind, but the real decision is which roles must be shielded from allocation to protect key endpoints. In many studies, it is not enough to blind participants. You must also blind the people who collect outcomes, because that is where subtle coaching, extra prompting, and selective interpretation creeps in. When endpoints rely on judgment, the outcome assessor is the most critical blind to protect, and the workflow should make it hard for them to see information that could reveal assignment.
Single blind typically means participants do not know assignment, but study staff do. This design is high risk when outcomes are subjective or when staff contact intensity can change outcomes. It can still be acceptable in some operational contexts, but it requires stronger controls and neutral scripts, and it increases the burden on monitoring. For teams building careers in trial oversight, understanding how single blind designs break is foundational training for a CRA career path and for progression into senior CRA roles where conduct risk becomes part of every decision.
Double blind is the common standard: participants and site staff interacting with them do not know assignment. It is not a label. It is a set of controls. You need allocation concealment, indistinguishable product presentation, neutral visit behavior, and strict emergency unblinding rules. A double blind trial still fails if staff can infer assignment from side effects, lab shifts, or kit patterns. That is why double blind designs must be paired with thoughtful randomization and concealment, using the discipline described in randomization techniques and reinforced through structured site documentation using CRF best practices.
Triple blind expands shielding to include the team analyzing outcomes or making certain adjudication decisions. This becomes important when interim looks, safety narratives, or coding decisions can create bias. It is also valuable when the endpoint is complex and requires adjudication, because adjudicators often make subtle judgments that can be pulled by expectation. To implement this well, you need role based system access and clean workflows that do not leak treatment information through comment fields, query text, or data exports. This is where trial operations intersects with data management, and why career tracks like clinical data manager and clinical data coordinator matter in blinding integrity.
3) Why blinding matters for credibility, statistics, and real decision making
Blinding is the cheapest insurance against biased effect sizes and inflated variance. Without blinding, you may still detect differences, but you cannot confidently claim they reflect biology rather than behavior. The clearest damage happens in subjective endpoints: pain, mood, fatigue, functional scores, and clinician rated scales. If participants believe they are on active treatment, they interpret symptoms differently and may push through discomfort. If they believe they are on control, they may disengage, seek additional care, or rate outcomes worse. That creates differential dropout, differential rescue medication use, and differential reporting, which can distort the treatment effect in either direction.
Blinding is also tied to operational consistency. When sites vary in how they explain the trial, the placebo response changes, and the treatment effect can shrink. When raters differ in how they administer scales, measurement error rises. When coordinators are overloaded, they may take shortcuts that change the participant experience. Each of those issues shows up as “noise,” but noise is not a neutral problem. It reduces power, increases sample size needs, and can make a viable program look dead. This is why teams invest in structured roles and career development for site and monitor leaders, such as a well trained CRC and an effective CRA who can intervene before drift becomes irreversible.
Blinding also strengthens safety interpretation. If adverse event reporting is biased by expectations, you can mistakenly attribute symptoms to disease progression in one arm and to drug exposure in the other. That distorts benefit risk thinking and can trigger unnecessary protocol changes that further damage the blind. A pharmacovigilance mindset helps teams spot these traps early, and it is why foundational understanding of pharmacovigilance supports better blinded trial conduct even before the product is approved.
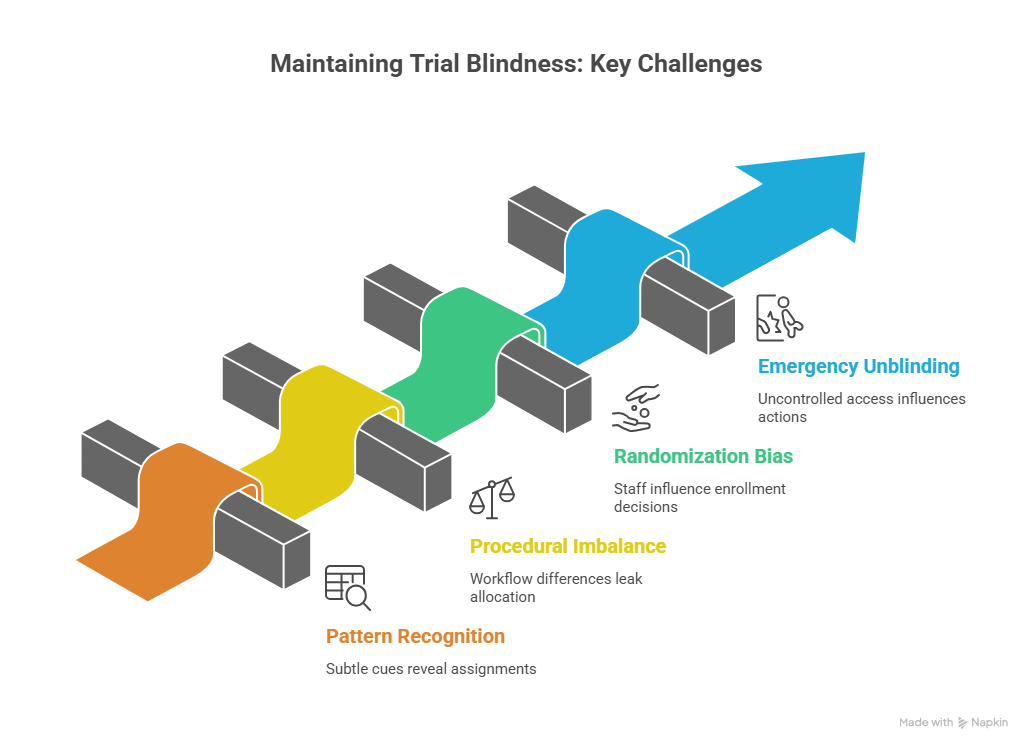
4) How blinding breaks in real trials and how to prevent each failure mode
Most unblinding is not dramatic. It is quiet pattern recognition. A participant reports a distinctive side effect. A nurse comments that “people on drug often feel this.” A coordinator notices that certain kit numbers correlate with symptoms. Over time, the site begins to act as if assignments are known. That shifts participant behavior and the tone of visits. To prevent this, you need strict neutral language, consistent scripts, and a culture where staff treat the blind as part of the endpoint. A good CRC is often the person who enforces this culture day to day.
Another common break is procedural imbalance. If one arm requires more visits, more labs, more check ins, or a different workflow, participants infer assignment. Even subtle differences, such as longer infusion time or different storage procedures, can leak allocation. Prevention requires harmonizing procedures across arms wherever possible and using role based access so only essential staff see treatment specific information. This is also where clean operational documentation matters. Your CRFs should be structured so site entries do not inadvertently reveal assignment through narrative. Strong guidance from CRF best practices reduces accidental leakage, and helps data teams identify patterns early.
Randomization related unblinding is especially damaging because it can introduce selection bias at enrollment. If staff suspect the next assignment, they may delay randomization, accelerate a “better candidate,” or subtly influence eligibility interpretation. This is not always malicious. It can be unconscious and still destructive. The fix is strong allocation concealment, secure centralized systems, and randomization strategies that resist predictability, as outlined in randomization techniques. Monitoring should look for suspicious patterns such as shifts in baseline severity, sudden changes in screen failure reasons, or unusual deviations around randomization timing. Skilled monitors build those instincts through core training like the CRA career guide and refine them as they move into clinical trial manager level oversight where trend detection becomes constant.
Emergency unblinding is another leak point. The moment one staff member learns assignment, it can influence how they talk, how they schedule visits, and what they document. To prevent this, emergency unblinding must be rare, justified, and handled through an independent process. The site must document the reason, the timing, and what actions followed, while still protecting the broader blind. If you do not capture this cleanly, the trial loses interpretability and it becomes harder to defend results under review.
5) Blinding across roles: participants, investigators, assessors, data, and safety
The most robust blinded trials are role designed. Participants are blinded to reduce expectation effects. Investigators are blinded to prevent differential care and interpretation. Outcome assessors are blinded to avoid measurement bias. Data management and statisticians may be blinded to reduce analytic bias and to prevent interim conclusions from shaping conduct. Safety teams may require limited unblinded access, but with firewalls that prevent allocation knowledge from reaching assessors or site staff.
Role separation becomes more important as trials become complex. If the same person is collecting outcomes, adjusting concomitant meds, counseling participants, and discussing safety, the risk of unblinding rises. Trials with high subjectivity need clearer separation between clinical interaction and endpoint measurement. That is why many teams build specialized roles, and why career tracks such as clinical research project manager and clinical operations manager exist to enforce consistent workflows across sites.
Data roles matter because unblinding can happen through the data layer. Poorly designed queries, free text fields, or inconsistent coding can reveal patterns. If data reviewers begin labeling symptoms as “typical of active drug,” that language can spread back to the site and shape behavior. Tight CRF structure, neutral query templates, and strong coding discipline reduce these leaks. Understanding the foundations of biostatistics also helps teams understand why even small data driven leaks can alter effect estimates when endpoints are sensitive.
Safety oversight needs special attention. Safety professionals must protect participants while preserving integrity. If safety communication is handled casually, it can reveal allocation. If site staff learn that certain lab shifts “mean drug,” they treat participants differently. A pharmacovigilance informed workflow, grounded in pharmacovigilance essentials, helps teams standardize AE elicitation and interpret safety patterns without leaking allocation across the study team.
6) FAQs about blinding in clinical trials
-
Allocation concealment prevents anyone from knowing the upcoming assignment before a participant is randomized. Blinding prevents participants and relevant staff from knowing assignment after randomization. Both protect against different biases, and a trial can be “double blind” on paper while still failing if allocation is predictable at enrollment. The most common real world failure is a site inferring assignments through patterns, which creates both selection bias and expectation bias. Strong use of centralized systems and approaches described in randomization techniques reduces these risks when implemented with discipline.
-
Subjective endpoints are highly sensitive to expectations and the social context of visits. If a participant believes they are on active treatment, they may report improvement earlier, rate severity differently, or tolerate symptoms longer. If a rater believes a participant is on active treatment, they may interpret answers more favorably or prompt differently. Objective endpoints reduce this vulnerability, but they do not eliminate it because behavior can still influence adherence, rescue use, and dropout. This is why teams pair endpoint discipline with strong documentation using CRF best practices.
-
Look for behavioral and data patterns. Participants start stating certainty about assignment. Certain sites show unusual response patterns. Rescue medication use differs sharply by site. Visit duration differs across participants in ways that correlate with symptoms. Screen failure reasons change over time. Endpoint variance grows mid study. Deviations cluster around dosing or assessments. Skilled monitors trained through the CRA definitive career guide often spot these signals earlier than dashboards do because they recognize how site behavior creates data signatures.
-
You assume side effects will drive guessing and design around it. Use neutral AE elicitation scripts and avoid leading questions. Standardize visit flow so “extra attention” does not correlate with suspected drug exposure. Reduce access to lab information that could reveal patterns, especially for outcome assessors. Use clear emergency unblinding rules to prevent convenience unblinding. Train staff to avoid confirming guesses through language or tone. Pair this with robust randomization and concealment from randomization techniques so predictability does not compound the leak.
-
Yes, but validity depends on the question and endpoint. Open label trials can still be rigorous when endpoints are objective, when biases are minimized through design, and when analysis plans anticipate behavioral confounding. However, open label designs increase the burden on standardization and monitoring, and they can be vulnerable to differential care, reporting, and dropout. If your decision depends on subjective outcomes, blinding is often the most efficient way to protect interpretability. Operational teams often learn this through roles that enforce consistency, such as clinical trial manager leadership and strong site execution.
-
CRFs should minimize free text that invites “typical drug effect” narratives. Use structured fields, clear definitions, and consistent time anchoring. Ensure adverse event and concomitant medication capture is standardized, not suggestive. Build neutral query templates so data cleaning does not imply allocation. Align source documentation with CRF fields to reduce interpretive gaps that trigger biased edits later. Practical guidance from CRF best practices helps prevent unblinding through documentation while improving audit readiness.
-
Monitoring protects blinding by catching behavior drift early. A monitor checks whether staff are using neutral scripts, whether visit procedures are consistent, whether randomization and kit handling remain secure, and whether documentation avoids allocation clues. Monitoring also detects trend level risks such as repeated deviations or site specific patterns that suggest unblinding. This is why the CRA roles and skills matter so much in blinded studies, and why strong monitors become key contributors to trial credibility rather than “box checkers.”