
Interactive GCP Compliance Self-Assessment Tool for Trial Sites
Good Clinical Practice only proves its value when a site can hold up under pressure. It is easy to feel compliant when visits are calm, queries are manageable, and enrollment is slow. Real weaknesses show up when screening accelerates, staff turn over, deviations start clustering, essential documents fall behind, and safety follow-up gets messy. That is why trial sites need more than a checklist. They need a self-assessment tool that exposes operational risk before a monitor, sponsor, auditor, or inspector does.
This guide breaks down how an interactive GCP compliance self-assessment tool should work, what domains it must measure, what site teams usually miss, and how to turn weak scores into corrective action. For Clinical Research Coordinators, Clinical Research Associates, Principal Investigators, Research Assistants, and Clinical Compliance Officers, this is the kind of tool that turns vague compliance talk into measurable control.

1. Why trial sites need a GCP compliance self-assessment tool instead of relying on assumptions
Most sites do not fail because they have never heard of GCP. They fail because they assume knowledge equals execution. Staff know that informed consent procedures matter, that essential training requirements under GCP must be current, that clinical trial documentation under GCP must be accurate, and that handling clinical trial audits requires discipline. But under workload, the site starts operating on habit, memory, and urgency rather than on controlled process. That is where self-assessment becomes valuable.
A strong self-assessment tool gives a site an honest picture of whether compliance is real, partial, or cosmetic. Cosmetic compliance is common. The regulatory binder looks organized, but version control is weak. Delegation logs exist, but responsibilities have drifted. Training records are complete, but staff cannot explain protocol-specific risks. Source notes are present, but chronology is inconsistent. These are exactly the kinds of cracks that later become sponsor escalation, monitoring findings, protocol deviations, or inspection pain. Teams that already understand GCP compliance strategies for clinical research coordinators, GCP compliance essentials for clinical research associates, managing protocol deviations, and research compliance and ethics usually recognize this gap faster than inexperienced teams.
Another reason a self-assessment tool matters is that most site risk is cumulative. A site rarely collapses because of one spectacular error. It gets exposed because consent corrections are slow, lab documentation is inconsistent, screening logs are incomplete, SAE follow-up is delayed, training evidence is patchy, and file maintenance lags just enough to show a pattern. When a site uses an interactive tool that scores these patterns regularly, it stops treating compliance as a once-a-year panic. It becomes part of ongoing operations, just like clinical trial protocol management, managing regulatory documents, effective data collection and management, and clinical trial auditing readiness.
The interactive part matters too. A static checklist often becomes lazy theater. People tick yes because the procedure exists somewhere. A real tool should force judgment. How current is training? How quickly are deviations escalated? Are CAPAs closed or actually effective? Can the PI explain oversight of delegated staff? Are informed consent notes traceable to the correct version and date? Interactive scoring makes the site confront operational truth. That is what separates a site that merely “has documents” from one that can defend its conduct under scrutiny.
| # | Assessment Domain | What the Tool Should Check | Typical Site Weakness | Risk Created | High-Value Corrective Action |
|---|---|---|---|---|---|
| 1 | Delegation control | Current responsibilities, signatures, supervision evidence | Tasks drift beyond formal delegation | Unqualified staff perform critical duties | Reconcile real workflow to delegation log monthly |
| 2 | Training currency | GCP, protocol, system, safety, amendment training status | Training done once and forgotten | Staff drift after amendments or turnover | Use role-based refreshers tied to study changes |
| 3 | Informed consent | Correct version, timing, signatures, note quality | Poor documentation of discussion process | Ethical and regulatory exposure | Audit consent packets and notes prospectively |
| 4 | Eligibility decisions | Source support for inclusion and exclusion criteria | Checklist completed without evidence review | Enrollment of ineligible subjects | Require second-person review for high-risk criteria |
| 5 | Source documentation | Contemporaneous notes, chronology, corrections, legibility | Retrospective note writing | Weak data credibility | Standardize visit note structure and correction rules |
| 6 | AE and SAE handling | Detection, escalation, timelines, follow-up completeness | Late awareness and weak narratives | Patient safety and sponsor trust risk | Create 24-hour escalation and follow-up tracker |
| 7 | IP accountability | Receipt, storage, dispensing, return, reconciliation | Logs updated after the fact | Dose traceability issues | Review accountability weekly during active dosing |
| 8 | Protocol deviations | Identification, reporting, root cause, CAPA | Deviation logs treated as passive record | Repeated mistakes remain active | Trend and classify deviations every month |
| 9 | Regulatory file health | Version control, missing essential documents, updates | Binder looks tidy but incomplete | Inspection gaps surface suddenly | Run missing-document review against master index |
| 10 | Screening and enrollment logs | Completeness, timely updates, reasons for screen failure | Logs updated only before monitor visits | Poor recruitment insight and traceability | Make logs part of daily or weekly workflow |
| 11 | Lab sample control | Collection timing, shipment, temperature, chain of custody | Operational shortcuts under pressure | Data validity and subject burden issues | Review pre-analytic errors monthly |
| 12 | EDC timeliness | Data entry delays, query aging, reconciliation status | Data backlog normalized | Late risk detection | Use aging thresholds with escalation triggers |
| 13 | PI oversight | Review frequency, delegation supervision, medical decisions | PI signs, but does not visibly oversee | Site accountability weakens | Create recurring PI oversight review agenda |
| 14 | Staff turnover resilience | Coverage plans, training handoff, continuity | Knowledge trapped with one person | Compliance drops when staff leave | Cross-train critical workflows |
| 15 | CAPA effectiveness | Whether fixes actually prevent recurrence | CAPAs close on paper only | Repeat findings continue | Re-check effectiveness after 30-60 days |
| 16 | Safety communication | Sponsor notification, internal escalation, medical review path | Unclear after-hours reporting | Late SAE submission | Use visible call tree and backup contacts |
| 17 | Version implementation | Protocol, ICF, manual, worksheet rollout | Old tools still in circulation | Inconsistent conduct across subjects | Use controlled retirement of obsolete forms |
| 18 | Monitoring response quality | Timeliness and quality of action item closure | Findings acknowledged but not fixed systemically | Same issues recur every visit | Map each finding to owner, deadline, CAPA |
| 19 | Subject retention follow-up | Missed visits, contact attempts, discontinuation reasons | Poor documentation of subject outreach | Data gaps and protocol drift | Track retention risk prospectively |
| 20 | Confidentiality control | Access restriction, PHI handling, document storage | Convenience overrides control | Privacy and compliance exposure | Audit access practices and shared folders |
| 21 | Protocol-specific procedures | Correct timing, windows, sequencing, documentation | Staff rely on memory instead of visit guides | Visit errors and missing assessments | Use visit-specific worksheets and pre-visit review |
| 22 | Document correction practice | Proper ALCOA-style correction behavior | Backdating or overwriting errors | Credibility damage during review | Retrain staff on compliant corrections with examples |
| 23 | Startup readiness | Documents, systems, supplies, delegation before first screen | Rushing activation before site is truly ready | First-subject errors appear early | Run readiness review before enrollment opens |
| 24 | Archive and retention planning | Closeout file logic, storage, retrievability | Thinking about retention too late | Closeout delays and missing evidence | Define archive structure before study end |
| 25 | Risk review cadence | How often the site reviews its own compliance signals | Only reacting before visits or audits | Slow recognition of emerging problems | Use monthly site-level compliance scorecards |
| 26 | Team communication | Escalation clarity, handoffs, study updates | Critical facts stay with one staff member | Missed actions and contradictory conduct | Adopt daily huddles for active studies |
| 27 | Inspection readiness | Ability to retrieve evidence and explain process | Site has documents but not narrative control | Poor performance under scrutiny | Practice mock interviews and document tracing |
2. What an effective interactive GCP compliance self-assessment tool should actually measure
A high-value tool should not ask generic questions like “Do you follow GCP?” That kind of wording produces meaningless confidence. The tool should measure behaviors, evidence, timeliness, and repeatability. It should force the site to prove process maturity across core areas such as GCP guidelines mastery, clinical trial protocol management, case report form best practices, and managing study documentation.
The first measurement category should be subject protection. That includes informed consent quality, documentation of consent discussions, handling of vulnerable participants, protection of confidentiality, protocol adherence at visits, and timely recognition of safety events. A site can have excellent data and still be weak in the area that matters most if subject protection is treated as routine paperwork. The tool should therefore score not just whether consent forms are signed, but whether the site can show the correct version, correct date, correct person obtaining consent, and proper source support. It should test whether the team can demonstrate good practice in patient safety oversight, adverse event handling, essential adverse event reporting techniques, and drug safety reporting requirements.
The second category should be data integrity. This means source quality, contemporaneous entry, ALCOA-style expectations, data entry timeliness, query management, reconciliation between source and EDC, and traceability of corrections. The reason many sites struggle here is not laziness. It is overload. Staff postpone entry, rely on memory, or copy forward weak notes. An effective tool catches these habits before they calcify. That is why it should align with biostatistics in clinical trials, primary vs secondary endpoints, effective data collection and management for research assistants, and clinical data coordinator responsibilities.
The third category should be operational control. This includes delegation, PI oversight, visit preparation, scheduling discipline, investigational product control, lab logistics, issue escalation, and monitoring follow-up. Many sites assume these are “operations problems,” not “compliance problems.” That is exactly the blind spot. GCP breaks down operationally before it breaks down formally. A missed temperature log, an outdated worksheet, a rushed dose accountability entry, or an ignored action item can become a direct compliance finding. A serious tool recognizes that relationship and scores it accordingly, just like strong teams do in laboratory best practices, clinical trial resource allocation, time management strategies for CRCs, and clinical trial project planning.
The fourth category should be quality response. Can the site identify recurring errors? Does it perform root cause analysis or just close findings quickly? Are CAPAs linked to real process changes? Does the site trend deviations, consent errors, query aging, or missing documentation? The best self-assessment tools do not end at scoring. They build a bridge from score to action, which is where real compliance maturity begins.
3. How trial sites should use the self-assessment tool to generate meaningful scores, not false reassurance
A self-assessment tool becomes dangerous when it is used performatively. If a site rushes through the questions, answers based on policy rather than actual study behavior, or lets one person grade their own work in isolation, the score becomes a shield against reality. The site feels reassured without becoming stronger. That is worse than having no tool at all. A real compliance culture treats scoring as evidence-based and occasionally uncomfortable. That mindset supports stronger clinical trial auditing readiness, better CRA monitoring interactions, clearer PI responsibilities, and more credible quality assurance careers.
The best way to use the tool is cross-functionally. The coordinator should not score delegation alone. The PI should not score oversight without challenge. Regulatory staff should not score file quality without matching what is actually happening at visits. A monitor-aligned perspective is useful even internally. Ask what a sponsor would see. Ask what an auditor would ask next. Ask whether the evidence exists in retrievable form or only in someone’s memory. That style of review strengthens managing regulatory documents for CRCs, clinical regulatory specialist workflows, clinical quality auditor development, and clinical compliance officer practice.
Scoring should also be tied to evidence levels. A good model uses tiers such as 0 for absent, 1 for inconsistent, 2 for present but weakly controlled, 3 for compliant and current, and 4 for compliant with monitoring or trending in place. That way the site can distinguish between having a process and controlling a process. For example, a deviation log that exists but is never trended should not get the same score as a log reviewed monthly with CAPA follow-up. Likewise, training files that are complete but not role-specific should score below a system that maps training to delegated tasks and amendments.
Timing matters as much as scoring design. Sites should not wait for panic moments. A new study should be assessed before first patient in. Active studies should be reviewed monthly or at least quarterly depending on complexity and enrollment speed. Assessments should also be triggered after major amendments, staff departures, sponsor escalations, or clusters of monitoring findings. This is the same practical discipline seen in effective stakeholder communication, clinical research team leadership, clinical operations manager development, and clinical research administrator leadership.
Most importantly, low scores should produce action, not shame. The point is not to prove the site is bad. The point is to identify where the system is fragile. Once a site understands that, the tool becomes operationally powerful rather than politically threatening.
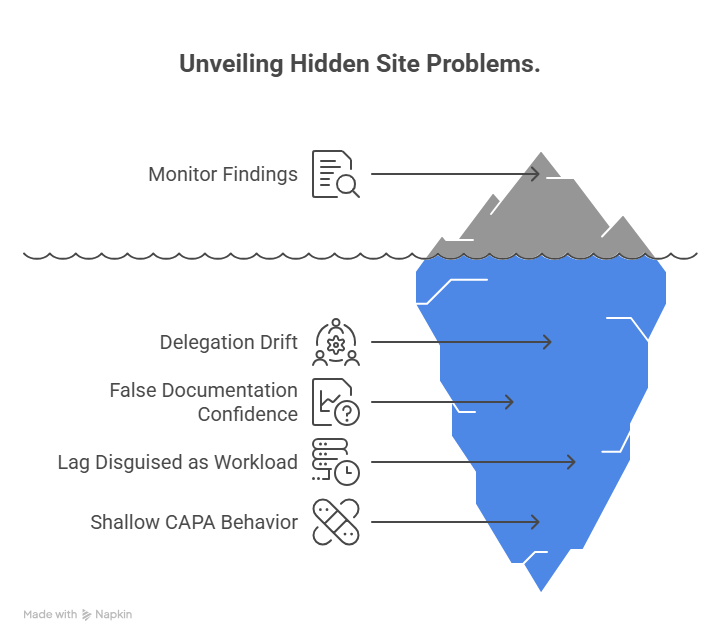
4. The site problems this tool should expose early before they turn into monitor findings or audit pain
The highest-value self-assessment tool is not the one with the prettiest interface. It is the one that reveals the ugly truths early. One common problem it should expose is hidden delegation drift. At many sites, the real workflow changes faster than the log. A coordinator begins reviewing eligibility nuances, a research assistant starts handling source corrections, or a backup staff member starts performing tasks that were never clearly trained or delegated. The site may still feel functional, but from a GCP perspective it is unstable. That is why the tool should force cross-checking between delegation, training, and actual conduct, just as disciplined teams do in clinical research coordinator certification preparation, CRA certification preparation, clinical trial assistant workflows, and sub-investigator responsibilities.
Another early warning area is false documentation confidence. A site may believe it documents well because every visit has a note. But the tool should test whether the note tells a coherent story, supports eligibility, explains missed procedures, documents safety follow-up clearly, and matches the EDC. This is where many sites discover that documentation exists without actually defending what happened. That weakness becomes expensive during clinical trial auditing, regulatory submissions review, medical monitor review, and scientific communication review.
The tool should also expose lag disguised as normal workload. Query aging, overdue data entry, incomplete follow-up on adverse events, outdated logs, unresolved action items, and backlogged binders often become culturally normalized. Staff start saying things like “we are only a little behind” or “we will clean it up before the next visit.” That is exactly the mindset the tool must punish with lower scores. Small delays become serious when they stack across multiple subjects and multiple studies. A site that catches lag early protects itself across clinical data manager responsibilities, lead clinical data analyst work, clinical trial manager workflows, and clinical research project manager execution.
A fourth problem area is shallow CAPA behavior. Sites often close findings with retraining because it is fast and easy to document. But if the root cause was workload imbalance, confusing worksheets, poor visit prep, unclear responsibility, or weak PI review, retraining alone will not solve it. The tool should therefore ask not only whether CAPAs exist, but whether recurrence rates fell, whether process changed, and whether ownership was clear. That is how the tool stops becoming a compliance quiz and starts becoming a site-improvement engine.
5. Best practices for building, scoring, and acting on a GCP self-assessment tool at trial sites
The best tools are simple enough to use regularly but demanding enough to expose weakness. That balance matters. If the tool is too abstract, sites answer aspirationally. If it is too complicated, they stop using it. The strongest design uses practical domains, evidence-based questions, weighted scoring for high-risk areas, and automatic prompts that suggest next actions when scores fall below a threshold. This is especially useful for teams working across clinical trial project planning, risk management in clinical trials, clinical trial budget oversight, and vendor management in clinical trials, where operational problems often create compliance consequences.
Weighting is one best practice sites underestimate. Not every failure carries the same risk. Missing a noncritical administrative update is not equivalent to weak informed consent control or poor SAE escalation. A smarter tool gives greater weight to subject protection, data integrity, and oversight failures. That makes the score more honest and helps leadership prioritize limited time. It also prevents false reassurance from “high average” scores built on low-risk items while serious gaps remain unresolved.
Another best practice is linking every question to evidence. If the tool asks whether protocol deviations are trended, it should prompt the user to identify the log, last review date, and resulting CAPA if one existed. If it asks whether PI oversight is visible, it should push for meeting notes, sign-off evidence, review cadence, or examples of direct intervention. When questions demand proof, teams stop answering from memory. This type of rigor directly strengthens principal investigator oversight, clinical research associate oversight, regulatory affairs specialist work, and quality assurance careers.
The next best practice is action mapping. A score by itself does not improve a site. The tool should assign risk bands such as green for controlled, yellow for vulnerable, orange for high-risk, and red for immediate action needed. But more importantly, each low score should produce an action path. That may include retraining, process redesign, weekly review cadence, PI involvement, sponsor clarification, worksheet revision, or targeted mock audit. This is where the tool becomes genuinely interactive and valuable.
Finally, the site should trend the tool’s results over time. A one-time score is a snapshot. Repeated scoring shows whether the site is improving, plateauing, or sliding. A high-performing site wants to know not only where it stands today, but whether its fixes are durable under real workload. That is the difference between compliance as an event and compliance as a managed system.
6. FAQs about an interactive GCP compliance self-assessment tool for trial sites
-
It is a structured tool that helps a research site measure how well its daily practices align with Good Clinical Practice requirements. Instead of waiting for sponsor findings or audit pressure, the site reviews its own controls across consent, safety, documentation, oversight, training, and operational discipline. This makes it highly relevant to GCP strategy, clinical trial documentation, research compliance and ethics, and clinical quality auditing.
-
A simple checklist often rewards surface-level answers. An interactive tool is better because it can force evidence-based scoring, prioritize high-risk areas, and suggest corrective actions based on weak responses. That makes it much more useful for real site control, especially in areas like protocol management, regulatory document management, AE reporting, and clinical trial auditing readiness.
-
The highest-priority domains are subject protection, informed consent, safety event handling, source documentation, data integrity, delegation control, PI oversight, and deviation management. These areas usually create the most serious findings when weak. Sites that measure them well tend to perform better in patient safety oversight, drug safety reporting, CRA oversight, and clinical compliance officer work.
-
At minimum, sites should complete it before first patient in, then at regular intervals during active conduct, especially after amendments, staff turnover, sponsor escalations, or repeated monitoring findings. High-risk studies may need monthly review. Lower-complexity studies may support quarterly review. The right frequency depends on study burden and risk, much like in clinical trial resource allocation, time management for CRCs, clinical operations management, and clinical trial manager workflows.
-
The best scoring is cross-functional. Coordinators, regulatory staff, investigators, quality personnel, and sometimes sponsor-facing staff should all contribute so the site does not grade itself from one narrow perspective. This makes the score more accurate and improves accountability across CRC responsibilities, CRA responsibilities, PI responsibilities, and research assistant roles.
-
The biggest mistake is treating it like a confidence exercise instead of a risk-detection exercise. When sites answer based on policy rather than evidence, score in isolation, or fail to act on weak areas, the tool becomes empty theater. Its real value comes from honest scoring, documented evidence, repeated use, and corrective action that actually changes site behavior. That mindset is what supports durable performance in mock audit readiness, CAPA discipline, quality assurance practice, and regulatory resilience.